
 职场资讯
职场资讯
正在查看高级数据挖掘柔和简历模板文字版
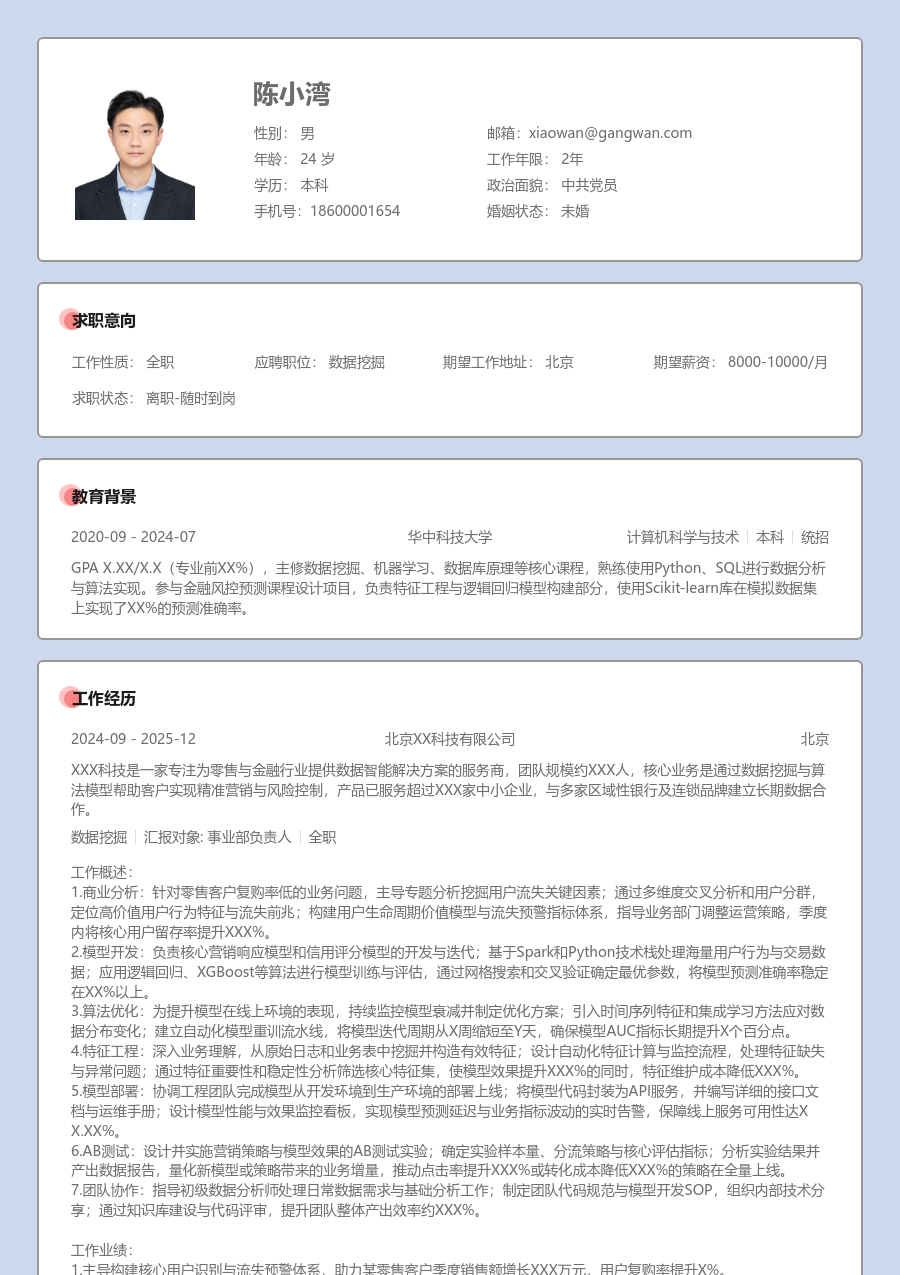
陈小湾
求职意向
工作经历
XXX科技是一家专注为零售与金融行业提供数据智能解决方案的服务商,团队规模约XXX人,核心业务是通过数据挖掘与算法模型帮助客户实现精准营销与风险控制,产品已服务超过XXX家中小企业,与多家区域性银行及连锁品牌建立长期数据合作。
工作概述:
1.商业分析:针对零售客户复购率低的业务问题,主导专题分析挖掘用户流失关键因素;通过多维度交叉分析和用户分群,定位高价值用户行为特征与流失前兆;构建用户生命周期价值模型与流失预警指标体系,指导业务部门调整运营策略,季度内将核心用户留存率提升XXX%。
2.模型开发:负责核心营销响应模型和信用评分模型的开发与迭代;基于Spark和Python技术栈处理海量用户行为与交易数据;应用逻辑回归、XGBoost等算法进行模型训练与评估,通过网格搜索和交叉验证确定最优参数,将模型预测准确率稳定在XX%以上。
3.算法优化:为提升模型在线上环境的表现,持续监控模型衰减并制定优化方案;引入时间序列特征和集成学习方法应对数据分布变化;建立自动化模型重训流水线,将模型迭代周期从X周缩短至Y天,确保模型AUC指标长期提升X个百分点。
4.特征工程:深入业务理解,从原始日志和业务表中挖掘并构造有效特征;设计自动化特征计算与监控流程,处理特征缺失与异常问题;通过特征重要性和稳定性分析筛选核心特征集,使模型效果提升XXX%的同时,特征维护成本降低XXX%。
5.模型部署:协调工程团队完成模型从开发环境到生产环境的部署上线;将模型代码封装为API服务,并编写详细的接口文档与运维手册;设计模型性能与效果监控看板,实现模型预测延迟与业务指标波动的实时告警,保障线上服务可用性达X
X.XX%。
6.AB测试:设计并实施营销策略与模型效果的AB测试实验;确定实验样本量、分流策略与核心评估指标;分析实验结果并产出数据报告,量化新模型或策略带来的业务增量,推动点击率提升XXX%或转化成本降低XXX%的策略在全量上线。
7.团队协作:指导初级数据分析师处理日常数据需求与基础分析工作;制定团队代码规范与模型开发SOP,组织内部技术分享;通过知识库建设与代码评审,提升团队整体产出效率约XXX%。
工作业绩:
1.主导构建核心用户识别与流失预警体系,助力某零售客户季度销售额增长XXX万元,用户复购率提升X%。
2.开发并迭代X个核心预测模型,平均AUC达
0.XXX,直接应用于精准营销与信贷审批场景,累计覆盖用户超XXX万。
3.建立模型全生命周期管理流程,将模型从开发到上线的平均时间缩短XXX%,线上模型稳定性提升XXX%。
4.通过AB测试驱动策略优化,累计实施超XXX次实验,推动关键业务指标平均提升X%以上。
5.培养与指导X名团队成员,团队项目交付及时率与质量评分均提升XXX%。
主动离职,希望有更多的工作挑战和涨薪机会。
项目经历
公司为某大型连锁超市打造的核心数据产品项目,原有粗放式营销导致用户触达不精准、营销成本高昂且ROI持续低于X。业务方需要基于千万级会员的线上线下行为数据,预测其未来X天内对特定品类商品的购买意向,以实现个性化优惠券推送,并解决模型响应延迟高、与现有CRM系统对接困难等技术瓶颈。
项目职责:
1.功能开发:负责用户画像构建与购买意向预测模型模块的开发,使用Spark进行大规模数据处理,应用XGBoost与深度学习算法进行多目标预测建模。
2.性能优化:通过特征降维与模型轻量化技术,将线上模型单次预测响应时间从XXX毫秒优化至XXX毫秒以内,满足实时接口调用要求。
3.技术攻坚:解决多数据源(POS、小程序、电商)合并时的数据一致性与时效性问题,设计流批一体特征计算管道,确保特征数据T+1更新。
4.质量保障:设计完整的离线评估与线上AB测试方案,建立模型效果监控与报警机制,确保模型上线后预测准确率波动范围小于X%。
项目业绩:
1.项目上线后,精准营销活动的用户点击率提升至X
X.X%,远高于行业平均X%的水平,季度营销成本节约XXX万元。
2.预测模型在测试集上的F1-score达到
0.XXX,成功集成进客户CRM系统,覆盖全量XXX万会员。
3.系统支持日均处理XXX万次预测请求,推动客户季度销售额环比增长X%,项目获评公司年度标杆案例奖。
教育背景
GPA X.XX/X.X(专业前XX%),主修数据挖掘、机器学习、数据库原理等核心课程,熟练使用Python、SQL进行数据分析与算法实现。参与金融风控预测课程设计项目,负责特征工程与逻辑回归模型构建部分,使用Scikit-learn库在模拟数据集上实现了XX%的预测准确率。
自我评价
培训经历
获得该认证后,将阿里云MaxCompute与DataWorks平台应用于实际数据仓库建设项目,主导设计了日处理TB级日志的数据分层模型与调度任务,使得数据产出时间提前X小时,数据计算资源成本优化XXX%。相关架构方案成为公司后续数据中台项目的参考模板。
高级数据挖掘柔和简历模板
适用人群: #数据挖掘 #高级[5-10年]










猜你想用










关于数据挖掘简历的常见问题
[基本信息]
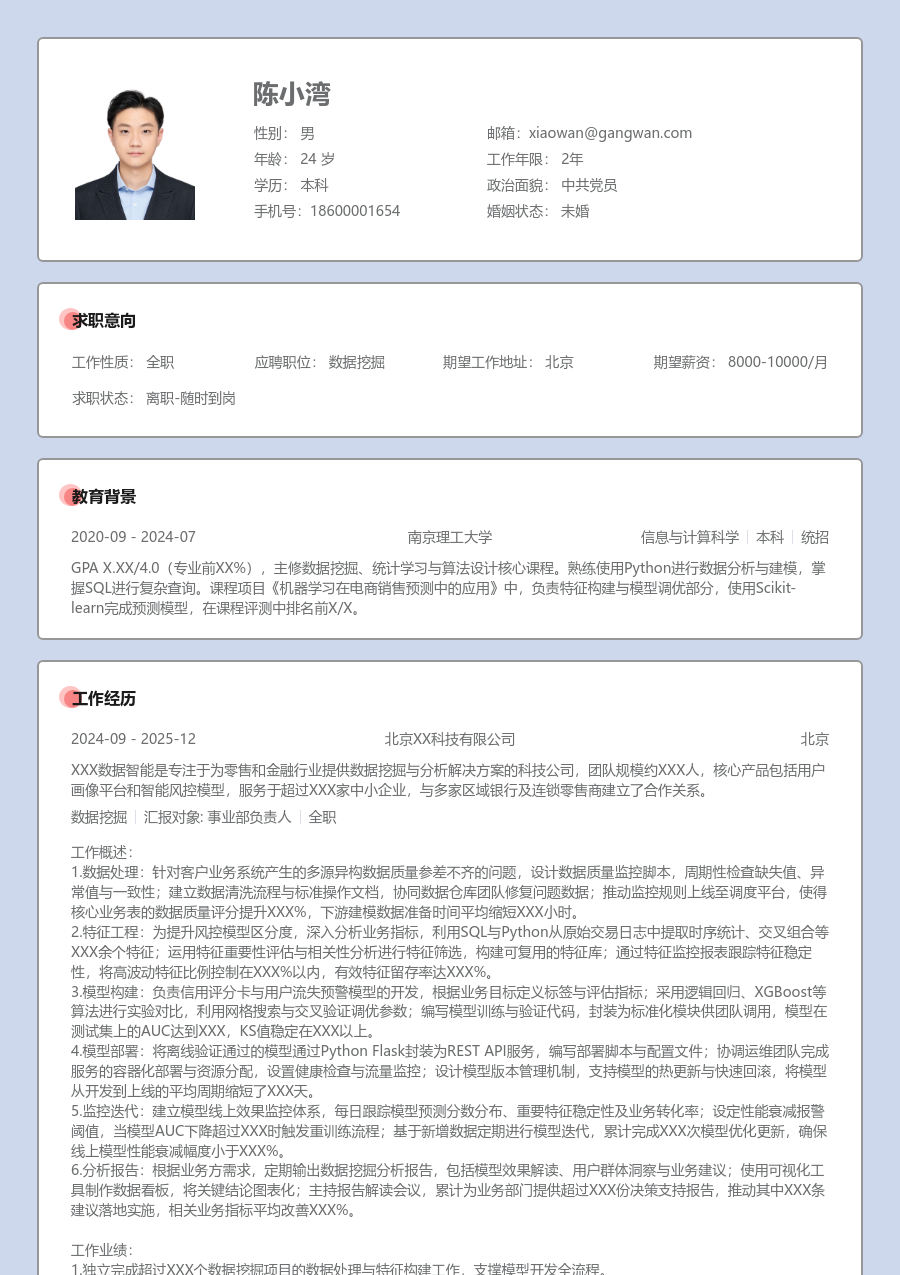
姓名:陈小湾
性别:男
年龄:26
学历:本科
婚姻:未婚
年限:4年
面貌:党员
邮箱:xiaowan@gangwan.com
电话:18600001654
[求职意向]
工作性质:全职
应聘职位:数据挖掘
期望城市:北京
期望薪资:8000-10000
求职状态:离职-随时到岗
[工作经历]
北京XX科技有限公司 | 数据挖掘
2024-09 - 2025-12
XXX科技是一家专注为零售与金融行业提供数据智能解决方案的服务商,团队规模约XXX人,核心业务是通过数据挖掘与算法模型帮助客户实现精准营销与风险控制,产品已服务超过XXX家中小企业,与多家区域性银行及连锁品牌建立长期数据合作。
工作概述:
1.商业分析:针对零售客户复购率低的业务问题,主导专题分析挖掘用户流失关键因素;通过多维度交叉分析和用户分群,定位高价值用户行为特征与流失前兆;构建用户生命周期价值模型与流失预警指标体系,指导业务部门调整运营策略,季度内将核心用户留存率提升XXX%。
2.模型开发:负责核心营销响应模型和信用评分模型的开发与迭代;基于Spark和Python技术栈处理海量用户行为与交易数据;应用逻辑回归、XGBoost等算法进行模型训练与评估,通过网格搜索和交叉验证确定最优参数,将模型预测准确率稳定在XX%以上。
3.算法优化:为提升模型在线上环境的表现,持续监控模型衰减并制定优化方案;引入时间序列特征和集成学习方法应对数据分布变化;建立自动化模型重训流水线,将模型迭代周期从X周缩短至Y天,确保模型AUC指标长期提升X个百分点。
4.特征工程:深入业务理解,从原始日志和业务表中挖掘并构造有效特征;设计自动化特征计算与监控流程,处理特征缺失与异常问题;通过特征重要性和稳定性分析筛选核心特征集,使模型效果提升XXX%的同时,特征维护成本降低XXX%。
5.模型部署:协调工程团队完成模型从开发环境到生产环境的部署上线;将模型代码封装为API服务,并编写详细的接口文档与运维手册;设计模型性能与效果监控看板,实现模型预测延迟与业务指标波动的实时告警,保障线上服务可用性达X
X.XX%。
6.AB测试:设计并实施营销策略与模型效果的AB测试实验;确定实验样本量、分流策略与核心评估指标;分析实验结果并产出数据报告,量化新模型或策略带来的业务增量,推动点击率提升XXX%或转化成本降低XXX%的策略在全量上线。
7.团队协作:指导初级数据分析师处理日常数据需求与基础分析工作;制定团队代码规范与模型开发SOP,组织内部技术分享;通过知识库建设与代码评审,提升团队整体产出效率约XXX%。
工作业绩:
1.主导构建核心用户识别与流失预警体系,助力某零售客户季度销售额增长XXX万元,用户复购率提升X%。
2.开发并迭代X个核心预测模型,平均AUC达
0.XXX,直接应用于精准营销与信贷审批场景,累计覆盖用户超XXX万。
3.建立模型全生命周期管理流程,将模型从开发到上线的平均时间缩短XXX%,线上模型稳定性提升XXX%。
4.通过AB测试驱动策略优化,累计实施超XXX次实验,推动关键业务指标平均提升X%以上。
5.培养与指导X名团队成员,团队项目交付及时率与质量评分均提升XXX%。
[项目经历]
项目名称:零售客户精准营销系统
担任角色:项目负责人
公司为某大型连锁超市打造的核心数据产品项目,原有粗放式营销导致用户触达不精准、营销成本高昂且ROI持续低于X。业务方需要基于千万级会员的线上线下行为数据,预测其未来X天内对特定品类商品的购买意向,以实现个性化优惠券推送,并解决模型响应延迟高、与现有CRM系统对接困难等技术瓶颈。
项目业绩:
1.项目上线后,精准营销活动的用户点击率提升至X
X.X%,远高于行业平均X%的水平,季度营销成本节约XXX万元。
2.预测模型在测试集上的F1-score达到
0.XXX,成功集成进客户CRM系统,覆盖全量XXX万会员。
3.系统支持日均处理XXX万次预测请求,推动客户季度销售额环比增长X%,项目获评公司年度标杆案例奖。
[教育背景]
华中科技大学
计算机科学与技术 | 本科
GPA X.XX/X.X(专业前XX%),主修数据挖掘、机器学习、数据库原理等核心课程,熟练使用Python、SQL进行数据分析与算法实现。参与金融风控预测课程设计项目,负责特征工程与逻辑回归模型构建部分,使用Scikit-learn库在模拟数据集上实现了XX%的预测准确率。