
 职场资讯
职场资讯
正在查看初级数据采集雅致简历模板文字版
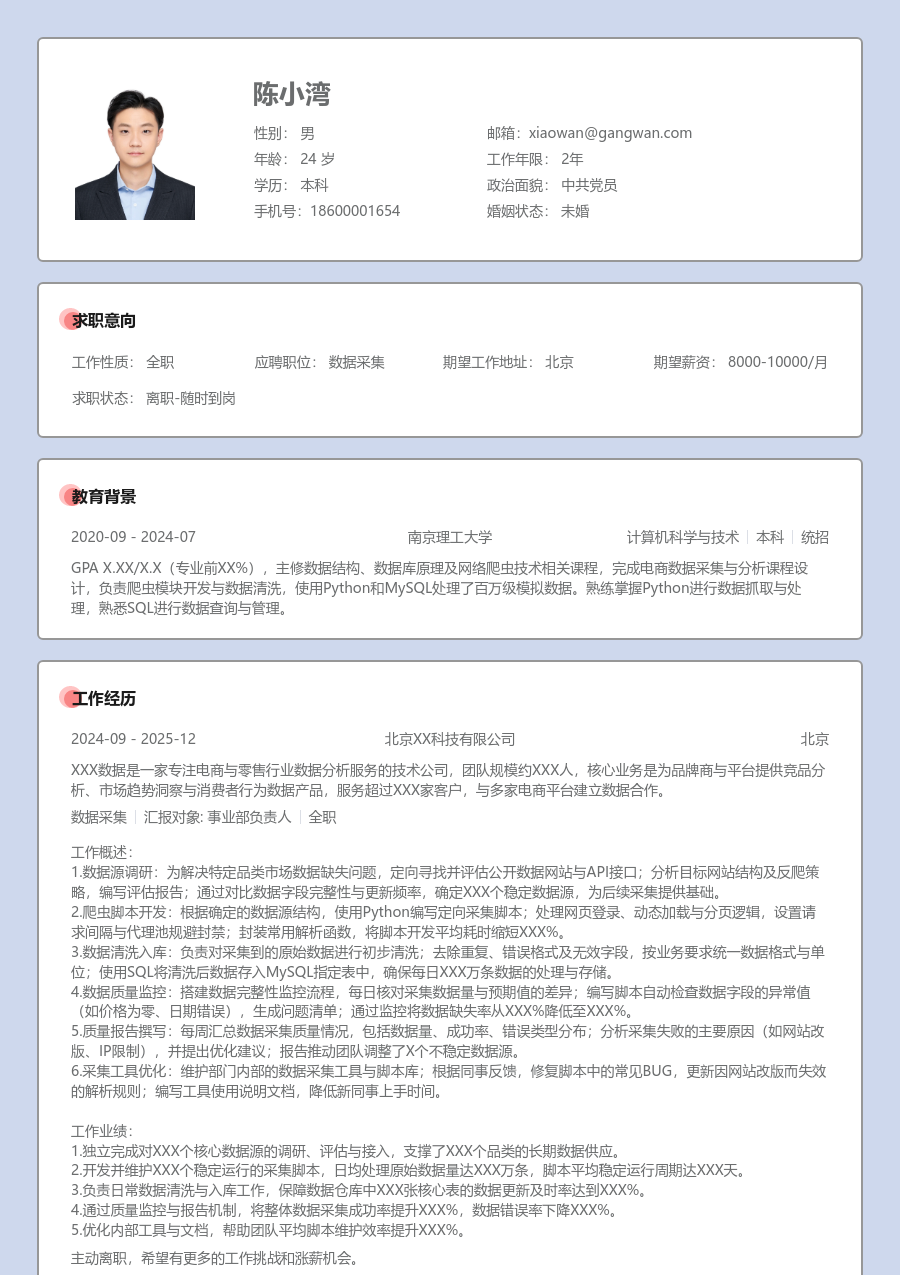
陈小湾
求职意向
工作经历
XXX数据是一家专注电商与零售行业数据分析服务的技术公司,团队规模约XXX人,核心业务是为品牌商与平台提供竞品分析、市场趋势洞察与消费者行为数据产品,服务超过XXX家客户,与多家电商平台建立数据合作。
工作概述:
1.数据源调研:为解决特定品类市场数据缺失问题,定向寻找并评估公开数据网站与API接口;分析目标网站结构及反爬策略,编写评估报告;通过对比数据字段完整性与更新频率,确定XXX个稳定数据源,为后续采集提供基础。
2.爬虫脚本开发:根据确定的数据源结构,使用Python编写定向采集脚本;处理网页登录、动态加载与分页逻辑,设置请求间隔与代理池规避封禁;封装常用解析函数,将脚本开发平均耗时缩短XXX%。
3.数据清洗入库:负责对采集到的原始数据进行初步清洗;去除重复、错误格式及无效字段,按业务要求统一数据格式与单位;使用SQL将清洗后数据存入MySQL指定表中,确保每日XXX万条数据的处理与存储。
4.数据质量监控:搭建数据完整性监控流程,每日核对采集数据量与预期值的差异;编写脚本自动检查数据字段的异常值(如价格为零、日期错误),生成问题清单;通过监控将数据缺失率从XXX%降低至XXX%。
5.质量报告撰写:每周汇总数据采集质量情况,包括数据量、成功率、错误类型分布;分析采集失败的主要原因(如网站改版、IP限制),并提出优化建议;报告推动团队调整了X个不稳定数据源。
6.采集工具优化:维护部门内部的数据采集工具与脚本库;根据同事反馈,修复脚本中的常见BUG,更新因网站改版而失效的解析规则;编写工具使用说明文档,降低新同事上手时间。
工作业绩:
1.独立完成对XXX个核心数据源的调研、评估与接入,支撑了XXX个品类的长期数据供应。
2.开发并维护XXX个稳定运行的采集脚本,日均处理原始数据量达XXX万条,脚本平均稳定运行周期达XXX天。
3.负责日常数据清洗与入库工作,保障数据仓库中XXX张核心表的数据更新及时率达到XXX%。
4.通过质量监控与报告机制,将整体数据采集成功率提升XXX%,数据错误率下降XXX%。
5.优化内部工具与文档,帮助团队平均脚本维护效率提升XXX%。
主动离职,希望有更多的工作挑战和涨薪机会。
项目经历
公司为服务某家电品牌客户发起的专项,需实时监控其XXX款产品在多个主流电商平台上的价格、促销及库存信息。初期依赖手动收集,效率低下且数据滞后严重,无法满足客户每日决策需求,面临采集目标网站频繁改版导致脚本大面积失效的风险。
项目职责:
1.负责采集方案设计:分析目标电商平台页面结构,针对商品详情页、列表页及搜索页设计不同的数据抽取方案,确定关键信息(价格、标题、优惠)的定位方式。
2.负责核心爬虫开发:使用Scrapy框架开发分布式爬虫,集成动态渲染与验证码识别模块以应对复杂页面,通过布隆过滤器去重,实现高效稳定的全量采集与增量更新。
3.负责监控模块搭建:开发数据质量监控脚本,对采集任务的完成率、响应时间及数据字段完整性进行实时报警,确保问题在XXX小时内被发现。
4.协助部署与维护:将爬虫部署至公司服务器集群,配置定时任务与日志系统,定期巡检并修复因网站改版导致的采集失败问题。
项目业绩:
1.成功接入并稳定监控X个主流电商平台,覆盖目标商品SKU超过XXX个,数据采集准时率达到XXX%。
2.将客户所需的全平台价格数据产出时间从原来的人工X天缩短至系统自动化的X小时内,效率提升XXX%。
3.通过稳定的数据供应,帮助客户在季度促销活动中及时调整定价策略,其线上渠道销售额环比提升XXX%。
4.项目积累的爬虫框架与监控方案,被复用到其他X个类似客户项目中,减少了重复开发工作量。
教育背景
GPA X.XX/X.X(专业前XX%),主修数据结构、数据库原理及网络爬虫技术相关课程,完成电商数据采集与分析课程设计,负责爬虫模块开发与数据清洗,使用Python和MySQL处理了百万级模拟数据。熟练掌握Python进行数据抓取与处理,熟悉SQL进行数据查询与管理。
自我评价
培训经历
系统学习了数据分析全流程方法论,包括数据采集、处理、建模与可视化。将数据质量控制的理念应用于日常工作,优化了采集数据的事后校验规则,使得入库数据的字段错误率下降了XXX%。认证知识帮助更好地理解下游业务部门的数据需求,使采集的数据更具可用性。
初级数据采集雅致简历模板
适用人群: #数据采集 #初级[1-3年]














关于数据采集简历的常见问题
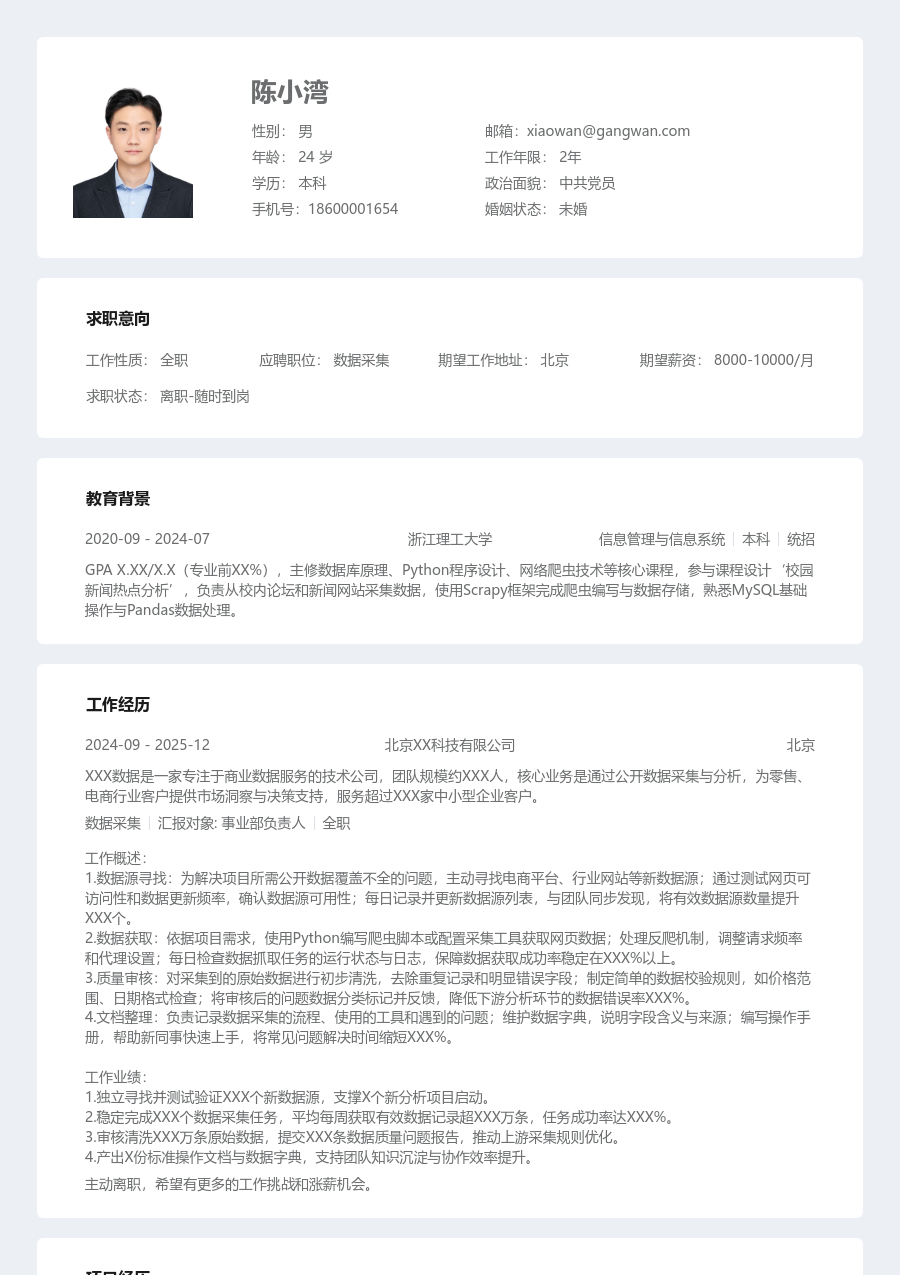
[基本信息]
姓名:陈小湾
性别:男
年龄:26
学历:本科
婚姻:未婚
年限:4年
面貌:党员
邮箱:xiaowan@gangwan.com
电话:18600001654
[求职意向]
工作性质:全职
应聘职位:数据采集
期望城市:北京
期望薪资:8000-10000
求职状态:离职-随时到岗
[工作经历]
北京XX科技有限公司 | 数据采集
2024-09 - 2025-12
XXX数据是一家专注电商与零售行业数据分析服务的技术公司,团队规模约XXX人,核心业务是为品牌商与平台提供竞品分析、市场趋势洞察与消费者行为数据产品,服务超过XXX家客户,与多家电商平台建立数据合作。
工作概述:
1.数据源调研:为解决特定品类市场数据缺失问题,定向寻找并评估公开数据网站与API接口;分析目标网站结构及反爬策略,编写评估报告;通过对比数据字段完整性与更新频率,确定XXX个稳定数据源,为后续采集提供基础。
2.爬虫脚本开发:根据确定的数据源结构,使用Python编写定向采集脚本;处理网页登录、动态加载与分页逻辑,设置请求间隔与代理池规避封禁;封装常用解析函数,将脚本开发平均耗时缩短XXX%。
3.数据清洗入库:负责对采集到的原始数据进行初步清洗;去除重复、错误格式及无效字段,按业务要求统一数据格式与单位;使用SQL将清洗后数据存入MySQL指定表中,确保每日XXX万条数据的处理与存储。
4.数据质量监控:搭建数据完整性监控流程,每日核对采集数据量与预期值的差异;编写脚本自动检查数据字段的异常值(如价格为零、日期错误),生成问题清单;通过监控将数据缺失率从XXX%降低至XXX%。
5.质量报告撰写:每周汇总数据采集质量情况,包括数据量、成功率、错误类型分布;分析采集失败的主要原因(如网站改版、IP限制),并提出优化建议;报告推动团队调整了X个不稳定数据源。
6.采集工具优化:维护部门内部的数据采集工具与脚本库;根据同事反馈,修复脚本中的常见BUG,更新因网站改版而失效的解析规则;编写工具使用说明文档,降低新同事上手时间。
工作业绩:
1.独立完成对XXX个核心数据源的调研、评估与接入,支撑了XXX个品类的长期数据供应。
2.开发并维护XXX个稳定运行的采集脚本,日均处理原始数据量达XXX万条,脚本平均稳定运行周期达XXX天。
3.负责日常数据清洗与入库工作,保障数据仓库中XXX张核心表的数据更新及时率达到XXX%。
4.通过质量监控与报告机制,将整体数据采集成功率提升XXX%,数据错误率下降XXX%。
5.优化内部工具与文档,帮助团队平均脚本维护效率提升XXX%。
[项目经历]
项目名称:电商平台竞品价格监控系统
担任角色:项目负责人
公司为服务某家电品牌客户发起的专项,需实时监控其XXX款产品在多个主流电商平台上的价格、促销及库存信息。初期依赖手动收集,效率低下且数据滞后严重,无法满足客户每日决策需求,面临采集目标网站频繁改版导致脚本大面积失效的风险。
项目业绩:
1.成功接入并稳定监控X个主流电商平台,覆盖目标商品SKU超过XXX个,数据采集准时率达到XXX%。
2.将客户所需的全平台价格数据产出时间从原来的人工X天缩短至系统自动化的X小时内,效率提升XXX%。
3.通过稳定的数据供应,帮助客户在季度促销活动中及时调整定价策略,其线上渠道销售额环比提升XXX%。
4.项目积累的爬虫框架与监控方案,被复用到其他X个类似客户项目中,减少了重复开发工作量。
[教育背景]
南京理工大学
计算机科学与技术 | 本科
GPA X.XX/X.X(专业前XX%),主修数据结构、数据库原理及网络爬虫技术相关课程,完成电商数据采集与分析课程设计,负责爬虫模块开发与数据清洗,使用Python和MySQL处理了百万级模拟数据。熟练掌握Python进行数据抓取与处理,熟悉SQL进行数据查询与管理。